Passagens Aéreas e a Oferta Escassa
Já é bem conhecido o fato de que o preço de uma passagem aérea não tem relação nenhuma com o tamanho do percurso, e sim com a oferta e a demanda. Os preços das passagens são sugeridos por softwares complexos cujos objetivos principais são maximizar as receitas do vôo e minimizar a quantidade de assentos livres. O matemático Keith Devlin cita que há ainda os objetivos secundários de atrair usuários de outras companhias aéreas, e de criar lealdade entre aqueles que se utilizam frequentemente de serviços aéreos.
A partir das capacidades das aeronaves, quantidades de assentos de cada tipo, capacidades dos aeroportos destinados à companhia, dados históricos e sazonalidade, o software sugere preços dos bilhetes, tentando sempre maximizar a receita. Há também regras para estimular que os vôos sejam reservados com antecedência, permitindo melhor planejamento por parte da empresa aérea, e outras para estimular a utilização de dias e horários de baixos volumes, ou mesmo de aeroportos com maior capacidade ociosa. Há ainda regras que tentam identificar o cliente que está viajando a negócios e o cliente que viaja a passeio, para poder extrair o maior valor possível de cada público. O preço depende tanto desta logística complexa, e tão pouco da distância do trecho em si, que ocorrem casos onde é mais barato ir de São Paulo à Miami para depois voltar a Caracas, do que o vôo direto de São Paulo à capital Venezuelana.
Já que as companhias, os aeroportos e a própria malha aérea tem recursos limitados, a oferta de serviços aéreos como um todo é limitada. Se a oferta é limitada, priorizam-se os clientes mais rentáveis, em detrimento daqueles que não estão dispostos a pagar tanto quanto os primeiros. Em outras palavras, se houvesse recursos infinitos (aeroportos, aeronaves e espaço aéreo), a oferta aumentaria e os preços das passagens cairiam para valores mais próximos dos custos reais do serviço.
Este modelo de precificação, baseado na necessidade do cliente (e na oferta dos concorrentes) se opõe ao mais conhecido modelo de precificação por margem (markup), onde o preço é definido a partir dos custos (do produto ou serviço) somados a uma margem bruta de lucro. Os consumidores costumam ter a percepção de que o markup é um método mais “justo” de precificação, pois o preço fica intimamente ligado ao custo do produto/serviço, e não tanto à lei da oferta e demanda, tampouco ao quanto cada consumidor pode ou está disposto a pagar.
Software e o Custo Marginal Zero
Quando se fala em precificação de Software, a diferença principal é o custo marginal. O custo marginal de um software, seja ele disponibilizado na internet, ou mesmo gravado em CD, é infinitamente menor do que o custo de desenvolvimento deste. Temos então uma economia de escala, já que o aumento da produção (distribuição) fará o custo médio cair, à medida que os custos fixos são diluídos em grandes volumes.
Se desprezarmos os custos promocionais (e despesas de venda), e considerarmos um software sendo vendido em meio puramente eletrônico (ou seja, via download, que tem custo desprezível), qualquer preço acima de 1 R$ já é lucrativo. Milhares de pequenos fabricantes de software já comercializam seus softwares seguindo este modelo, cujo exemplo mais famoso dos últimos tempos é a Apple Store (iTunes Store), onde os usuários podem comprar diversos programas para o iPhone a preços que vão desde o gratúito até umas poucas dezenas de dólares, passando por toda gama de preços imagináveis.
Mas o fato de ter custo de distribuição desprezível significa que todo software deve ser comercializado por valores próximos do seu custo de distribuição? Obviamente não.
Preço Ótimo
Suponha que um determinado software possua a curva de demanda abaixo.
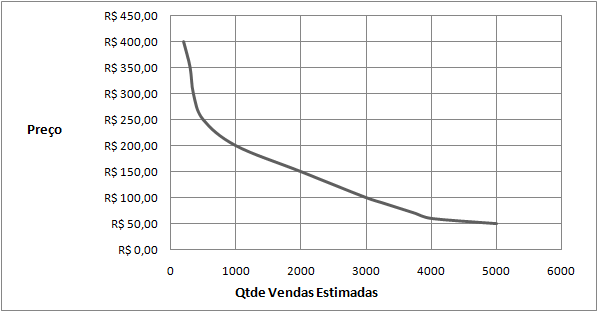
A curva exibe o número de clientes que comprariam o software para cada possível preço entre 50 e 400 R$. Suponha agora que o custo por cada unidade vendida é de 30 R$ (incluindo CD, manual, caixa, e correio). Vamos calcular os lucros para cada um dos possíveis preços:
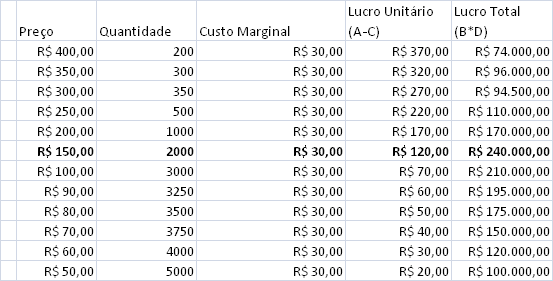
Como se pode observar, os maiores lucros se dão com o preço de 150 R$.
Se a tabela acima for colocada em um gráfico comparando o preço de venda sugerido e o lucro total esperado (lucro unitário x quantidade esperada), podemos visualizar melhor que o valor ótimo é realmente próximo de 150 R$.
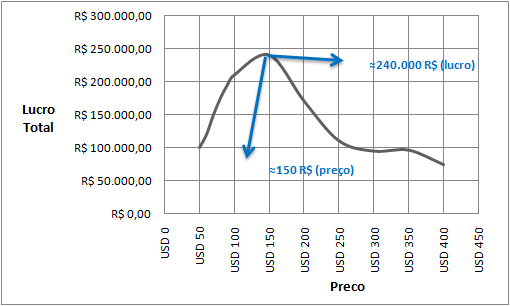
É comum que no processo de precificação que o empresário tente relacionar o preço ao valor investido no desenvolvimento do produto, mas isto é totalmente desnecessário. Segundo Joel Spolsky, o investimento que você fez no desenvolvimento do seu software é custo irrecuperável (sunk cost). A partir do produto pronto, você quer maximizar seus lucros, e este cálculo de maximização não depende do quanto você investiu no seu produto.
Na prática, não é tão fácil chegar ao preço ótimo. Não há como se estimar a curva de demanda, a não ser de maneira empírica, e para dificultar ainda mais, a curva de demanda pode nem ser decrescente, pois muitos consumidores ainda acreditam que a qualidade de um produto é diretamente proporcional ao seu preço (“you get what you pay for”). Tampouco é desejável fazer constantes ajustes nos preços para medir a curva de demanda.
Segundo Eric Sink, a melhor forma de definir o preço do seu software é pensar no seu posicionamento em relação aos seus concorrentes, e definir um preço que seja consistente com este posicionamento perante eles.
Segmentação
Em economia, o Excedente do Consumidor corresponde à diferença entre o valor que o consumidor estaria disposto a pagar por um bem e o valor que ele efetivamente paga.
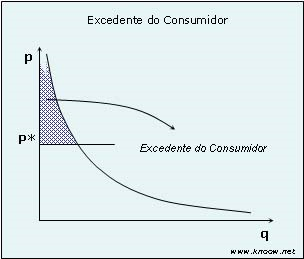
Para que o empresário possa “capturar” este excedente, o que economicamente chama-se de “anular” o excedente do consumidor, pode-se recorrer a preços diferenciados ajustados à curva de procura. Ou seja, desenvolvem-se variações do produto, focando cada variação para determinado segmento, tentando extrair o máximo valor em cada segmento.
No mercado de software, esta segmentação tradicionalmente é feita através do desenvolvimento de uma versão completa, que depois é desmembrada para gerar versões simplificadas, com menos funcionalidades ou módulos.
É importante ter cuidado para não se criar um número muito grande de versões (segmentos), corendo o risco de confundir o consumidor. Eric Sink sugere que o software seja segmentado sempre em 3 camadas: 1) A camada mais inferior é a “Standard Edition,” oferecendo conjunto de funcionalidades muito básicas e um preço muito baixo; 2) A camada intermediária é a “Professional Edition,” feita para o maior segmento do seu mercado; 3) A camada superior é a “Enterprise Edition,” incluindo toda funcionalidade imaginável e precificada muito acima.
Para exemplificar o resultado financeiro da segmentação, vamos supor que no exemplo da sessão anterior o empresário ao invés de lançar seu software ao preço ótimo de 150 R$ (que lhe daria um lucro de 240.000 R$), resolva lançar 3 versões: a) Enterprise a 300 R$; b) Professional a 150 R$; c) Standard a 50 R$.
Supondo que cada consumidor adquira o produto na versão mais cara que ele está disposto a pagar, temos que:
a) Há 350 pessoas que pagariam até 300 R$, então comprariam a versão Enterprise por 300 R$.
b) Há 2000 pessoas que pagariam até 150 R$. Descontando as 350 pessoas anteriores (que compraram a versão Enterprise), sobram 1650 pessoas comprando a versão Professional por 150 R$.
c) Há 5000 pessoas que pagariam até 50 R$. Descontando as 2000 pessoas anteriores (que compraram a versão Enterprise ou a Professional), sobram 3000 pessoas comprando a versão Standard.
Temos então um lucro quase 47% maior do que teríamos com uma única versão (240.000 R$):

Para utilizar um exemplo real, podemos citar o Microsoft Office 2007. Sabemos que a maioria absoluta dos usuários deste programa só utiliza o Excel, Word, Outlook, e raramente o Powerpoint. Temos então a versão “Home and Student” que dos 4 programas citados só não possui o Outlook (que pode ser substituído pelo Outlook Express gratuito) e custa apenas 150 USD. Passando este segmento de entrada (versão Home and Student), todas as outras versões (Standard, Small Business, Professional e Ultimate) possuem os 4 aplicativos principais, e possuem preços variando entre 400 USD a 680 USD, variando em funcionalidades que são inúteis para a maioria absoluta dos usuários. No entanto, apesar de as versões serem quase idênticas, as empresas costumam comprar de acordo com seu porte e poder aquisitivo, aproximando-se inconscientemente da curva de demanda e reduzindo o excedente do consumidor.
O empresário e escritor Joel Spolsky critica o modelo de segmentação usado pela Oracle, SAP, e diversas outras start-ups inspiradas nos modelos deles, que fazem a segmentação através do modelo que ele chama de “Quanto dinheiro você têm?”. Joel explica que a Oracle não divulga preço de seus produtos em nenhum lugar, e que a única forma de obter preços é preencher formulário de contato, através do qual um vendedor faz contato com o cliente e tenta descobrir o quanto o cliente pode pagar. O autor explica que este modelo não só afugenta os compradores pequenos (que presumem que o preço é alto e não poderão pagar), como afugenta os compradores que não gostam de vendedores (fato já conhecido no segmento do varejo).
“Software as a Service” e o Preço Justo
O “Software as a Service” (SaaS) é basicamente uma nova forma de comercialização de software, onde o usuário não compra licenças sobre o software, mas sim as aluga. Tecnologicamente o SaaS é igual ao software tradicional, com a diferença de que normalmente o usuário não instala o software em seu próprio computador, executando-o diretamente dos servidores do fornecedor (através da internet).
Em sua forma mais comum, a cobrança de utilização de um serviço SaaS é feita por número de usuários e período de utilização. Para exemplificar, vamos supor que a Coca-Cola tenha 50 vendedores que se utilizam do software SalesForce, e paga 10 USD por cada usuário-mês. Ao longo de 1 ano, a Coca-Cola terá pago a SalesForce o valor de 6000 USD (12 meses * 50 funcionários * 10 USD).
Para efeito de comparação, caso a SalesForce vendesse licenças no modelo tradicional ao preço de 240 USD cada, a Coca-Cola teria comprado 50 licenças de utilização de seu software e teria pago o mesmo valor que ela paga em 24 meses no modelo SaaS (12.000 USD). Apesar de no modelo tradicional o cliente ter efetivamente propriedade sobre a licença (e o direito de continuar usando), ao final destes 24 meses o software adquirido pela Coca-Cola no modelo tradicional possivelmente já estaria defasado, caso a SalesForce tenha lançado uma versão mais nova. O cliente teria que decidir entre adquirir a nova versão do Software ou continuar com a versão antiga. Já no modelo do SaaS, as atualizações são sempre disponíveis, pois você está sempre pagando para ter direito de utilizar a “última versão”.
Uma vantagem óbvia para os clientes, é que o modelo SaaS é mais flexível à variações na demanda de utilização. Se, por exemplo, a Coca-Cola aumentasse o número de funcionários para atender uma demanda sazonal, bastaria pagar pelas licenças adicionais pelo período adicional, e ao término da demanda ela deixa de utilizar o software e deixa de pagar as licenças. Ou seja, o modelo é flexível, e os custos são diretamente proporcionais à utilização efetiva.
Mas as vantagens são ainda maiores. Conforme explicado anteriormente, o modelo clássico de precificação SaaS é cobrar por usuários e por período, no entanto, como o SaaS costuma ser gerenciado pelo próprio fornecedor, este têm um controle exato sobre o quanto e como o cliente está utilizando, e permite ao fornecedor calcular com precisão o quanto seu serviço é valioso para o cliente, e cobrar de acordo. Ou seja, o SaaS permite modelos de precificação mais elaborados, que consigam medir a real utilização do cliente, ou mesmo medir o quão valioso é o cliente, como por exemplo: cobrar um percentual sobre as vendas feitas através do software; cobrar de acordo com o giro do estoque; cobrar pelo número de telefonemas atendidos no call-center; cobrar de acordo com o número de funcionários para os quais o software está gerando a folha de pagamento; cobrar pelo número de emails enviados.
Para o cliente, o modelo de cobrança fica “justo”, e ele entende que a razão entre o benefício recebido e o valor cobrado é o mesmo para todos os outros clientes. Para o fornecedor, o modelo dispensa a necessidade de segmentar o produto (e consequentemente poupa esforço de estratégia de preços, posicionamento e promoção), pois permite ao fornecedor cobrar de acordo com o benefício recebido pelo cliente, e mais ainda, permite que o benefício recebido pelo cliente seja efetivamente benefício enxergado, pois o critério de cobrança é objetivo, tangível e mensurável. John Desmons aponta ainda que o fato do SaaS garantir receita recorrente é muito benéfico para ambos cliente e fornecedor, pois facilita previsão do fluxo de caixa.
Apesar de parecer inovador, o conceito de cobrar software e hardware de acordo com a utilização não é nenhuma novidade. Este modelo já tem sido usado há muitos anos pelos fabricantes de Mainframes como a IBM e a Unisys, que costumam emprestar seus supercomputadores para os clientes (como bancos), e cobram mensalmente de acordo com a utilização medida. Ou seja, a IBM empresta 6 ou 7 mainframes para Banco Itaú, mede mensalmente qual foi a utilização destas máquinas (em MIPS, milhões de instruções executadas), e envia a fatura. Se os mainframes estão com muita capacidade ociosa, a IBM leva embora alguns deles; se eles estão sobrecarregados, a IBM empresta mais máquinas para o Banco. Além do SaaS, a tecnologia de “Cloud Computing” também segue o mesmo modelo de precificação baseado em oferecer recursos ilimitados e cobrar de acordo com a utilização medida.
Conclusão
Voltando às passagens aéreas e ao custo marginal, se os aviões e vôos custassem poucos dólares e pudéssemos transportar número infinito de pessoas pelos ares, a precificação de passagens aérea seria exatamente como precificar software tradicional. Se além destas condições, a companhia aérea ainda pudesse identificar o quanto o vôo agregou para cada passageiro, identificando, por exemplo , quais dentre os executivos efetivamente fecharam bons negócios, ou quem sabe até identificar quanto dinheiro cada passageiro têm, e cobrar proporcionalmente com base nestes valores, neste caso estariamos precificando de forma tão justa quanto o SaaS.
Pagar por utilização de um software é como pagar pelos litros que você abasteceu no posto de gasolina, ou pelo peso da comida que você comeu no restaurante por kilo. É como pagar pelos minutos que você usou no seu celular, pagar tributos proporcionais à sua renda ou à sua movimentação financeira, ou pagar o boliche pelo tempo que você permaneceu jogando. É como sua conta de luz, sua conta de gás, e sua conta de água. É justo, consistente, e trata todos clientes como iguais. Definitivamente, o SaaS veio para revolucionar a forma como se comercializa software, e quem sabe até pra mudar toda a forma como os consumidores enxergam o conceito de “preço justo”.
Referências
1. Joel Spolsky: Camels and Rubber Duckies
2. Eric Sink: Product Pricing Primer
3. Keith Devlin: The crazy math of airline ticket pricing
4. John Desmons: [Software as a Service Gaining as a Pricing Model](http://www.softwaremag.com/L.cfm?Doc=1029-3/2007